搜索到
19
篇与
技术
的结果
-
 关于 BootLoader 有过刷机经验或者曾经尝试过刷机的童鞋,一定听说过「解锁」这个词。这里的「解锁」全称应该是「解锁 BootLoader」或者简称为「解 BL 锁」。与通过人脸识别或者指纹、数字图案解锁手机屏幕的那种「屏幕解锁」不同,这里的「解锁」完全是另外一个概念。直观来说,解 BL 锁是刷机的前提条件。通常情况下,一旦某个设备无法解锁 BL,基本上就无法在这个设备进行刷机了。那么,一定会有童鞋关心,解锁 BootLoader 到底意味着什么?为什么它会有限制?我们能绕过限制强制解锁吗?今天,我就尝试来回答一下这几个问题。在搞清楚解锁 BootLoader 之前,我们必须先搞清楚什么是 BootLoader:{callout color="#00ffff"}A bootloader is software that is responsible for booting a computer.{/callout}维基百科上的介绍言简意赅:Bootloader 是负责启动计算机的软件。计算机开机的时候,会执行一个相对较小的程序来初始化内存、外设等启动后续操作系统必备的资源,并最终启动用户所使用的操作系统(如 Windows, Android 等);这个程序就是 BootLoader。我们知道,操作系统负责管理设备的硬件资源;而 BootLoader 是用来启动操作系统的,如果有人通过 BootLoader 来启动一个恶意的操作系统,那我们设备的安全性就无法得到保障了。因此,BootLoader 一个核心的功能就是,确保启动一个可信的操作系统。另外,当设备的操作系统出现问题时,BootLoader 还可以引导启动另外一个正常的可信系统来执行恢复;所以,BootLoader 另外一个功能重要功能就是恢复系统。具体来说,BootLoader 是如何实现这两大功能的呢?以高通设备为例,我们看一下 BootLoader 的启动流程: 当我们按下电源键启动手机的时候,CPU 上电之后开始运行;它最开始运行的代码是 CPU 芯片厂商提供的,写死在某个只读存储上,这段代码一旦出厂便不可更改,我们通常称之为 BootROM 或者 PBL (Primary Boot Loader);PBL 的主要功能是上电自检并启动下一个组件 SBL(Secondary Boot Loader),现在被叫做 XBL (eXtended Boot Loader)。这个 SBL 主要是初始化一些硬件环境(如DDR, clocks 和 USB 等)和代码安全环境 (TrustZone),当然,最重要的还是验证并加载下一个组件——ABL(Android Boot Loader,也叫 aboot)。与 PBL 不同,SBL 程序一般存放在 eMMC 上,这个地方是可以被修改的,因此它可以被刷写和升级。正因如此,SBL 还承载着最底层的恢复设备的重任;我们常说的高通 9008 模式(全称 Emergency Download Mode)就运行在这里。9008 模式,本质上就是强制刷写设备的 eMMC 存储,因此不论你上层操作系统或者应用软件被破坏成什么样,除非硬件损坏,基本上都可以救回来。有童鞋会问,为啥要整个 SBL,直接 PBL 一把干完不行吗?实际上,PBL 是芯片相关的,芯片无法预知到它用什么外设,因此这两个阶段被解耦了。话说回来,SBL 执行完之后会验证并加载 ABL,ABL 的主要功能是从设备验证并加载 bootimg 然后启动 Linux Kernel 进而启动用户操作系统,根据选择的不同,可能会进入到 Android 系统或者 Recovery 模式。ABL 还有一个很重要的功能,它提供了一个 fastboot 协议,用户可以用 PC 通过 USB 连接设备,通过这个 fastboot 协议控制设备;我们通常所说的「线刷」,小米的兔子界面以及我们通过命令行工具 fastboot 刷机实际上就是运行在 ABL 下。正因 ABL 功能比较复杂,它内部其实运行着一个 mini 的操作系统,这个操作系统就是 lk(Little Kernel),顺带一提,Trusty TEE 可信执行环境下的操作系统以及 Google 新的 Fuchsia 的微内核 Zircon 也是基于 lk 的。ABL 启动 Linux Kernel 之后,内核最终会进入用户态执行 init,init 进而启动 ueventd, watchdogd, surfaceflinger 以及 zygote 等;zygote 启动之后 fork system_server 并启动各种 binder 服务,系统核心 binder 服务启动之后会启动 Launcher 桌面,这样整个系统就启动完毕了。联发科的设备 BootLoader 启动过程类似: 从上述 BootLoader 启动过程,我们可以很清楚地知道,BootLoader 的恢复功能体现在 SBL 阶段的恢复模式以及 ABL 阶段的 fastboot 线刷模式。实际上,在我们手机底层软件出现问题之后,不论是自己救砖还是去售后,基本都是用的这两种模式。在搞清楚了 BootLoader 的恢复功能之后,那在安全性方面,它又是如何保障的呢?细心的童鞋可能会注意到,上面我们多次提到了验证并加载。BootLoader 的各个启动过程串起来就是一个启动链,这个启动链的各个阶段在进行过渡和跳转的时候是需要进行验证的。也就是说,上一阶段在启动下一阶段的时候,会验证下一阶段的代码是否可信;只有在验证通过的情况下,整个启动过程才会继续进行。这就好比接力赛跑,在上一个选手把接力棒传递到下一个选手之前,他得先搞清楚是不是把接力棒交到了正确的伙伴手里;在现实世界中,这是通过五官和记忆来判断的;在计算里面,这个验证的过程实际上就是比对数字签名。如果 BootLoader 的每一个阶段都严格验证数字签名,在代码逻辑都正确的情况下,用户是无法通过 BootLoader 去加载一个修改过的第三方系统的(也就是无法刷机)。那么什么是解锁 BootLoader?解锁 BootLoader 实际上就是让 BootLoader 启动链上某些阶段的签名验证不生效。如果让 BootROM 不验证 SBL,那我们就可以任意加载 XBL 从而接管接下来的操作流程如 TEE,lk, Linux Kernel;如果让 SBL 不验证 ABL,那我们就可以任意加载 ABL 从而接管 lk 和 Linux Kernel;如果让 ABL 不验证 boot.img,我们就可以控制 Linux Kernel。在现实场景中,人们最需要的就是刷入自定义 boot.img,毕竟这是用户能接触到的最上层系统 Android 的一部分。修改 TEE 和 LK 理论上不是不可以,但是修改这部分人们感知不强,并且通常这部分组件并不开源,也让很多人无从下手。因此实际上,我们通常所说的解锁 BootLoader 特指让 ABL(aboot) 在加载 bootimage 时不进行验证。某些设备厂商提供了解锁功能,实际上就是通过某种方式关闭了 ABL 中对 bootimage 的加载验证。也许有童鞋会想,我们想办法篡改这个签名,那不是就可以解锁了?比如我们可以这样操作:把 bootimage 修改并用自己的签名,然后把 ABL 中存放签名的地方暴力改成我们的签名;这样 ABL 在校验签名的时候就会通过。但问题是,如果我们要修改 ABL 中存放签名的地方,势必要修改 ABL,那么 SBL 在加载 ABL 的时候就会验证签名不通过;这样的话,我们继续修改 SBL,然后把 PBL 中存签名的地方改掉?看起来或许可以。实际上,整个启动链之所以能保障安全,是因为它的信任传递机制——正因为第一个角色可信,第二个角色才可信,并一步步向下传递。如果有办法破坏掉启动链的第一个角色,那就破坏了整个信任链。所以,在 BootLoader 启动过程中,PBL(BootROM) 所持有的签名是所有安全的基石,也即信任根(Root of Trust)。在 BootLoader 中,有两个机制确保信任根受信:1.BootROM 的代码存放在只读存储器中,一旦出厂不可更改。2.下一阶段的可信数字签名存放在独有的硬件设备之中(eFuse,一次性可编程存储器),一旦写入就会被破坏(三星设备解锁之后会「熔断」指的就是类似特性)。因此,如果所有的组件都按照理想情况下工作,我们就无法更改 BootROM 所持有的信任根,进而无法破坏启动过程中的信任链,也就无法解锁设备。当然,一切建立在所有的代码都正常工作的条件下。一旦某个阶段的代码有漏洞,那我们就有希望突破信任链,进而强制解锁设备。事实上,这种漏洞并非天方夜谭。iOS 上著名的 checkmate 漏洞就是 BootROM 中的代码存在问题,通过这个漏洞人们可以越狱设备,甚至引导另外一个操作系统(比如在 iOS 上运行 Android)。联发科的芯片,也曾经出现过不少 BootROM 漏洞,比如 amonet 和 最近的 kamakiri。今年五月份的安全更新中,CVE-2021-0467 也是一个 BootROM 漏洞。如果设备提供商偷懒,并没有完整地实现整个安全启动链,那也是可能强制解锁的。比如老的华为设备,其解锁码存放在 proinfo 分区下,这个分区是可以被刷写的;因此你可以拿别的设备的解锁码和 proinfo 分区刷入直接通过验证。还有,曾经的 vivo 对 bootimage 的验证并不严格,用户自定义一个 fastboot 就可以直接解锁。总体来说,如果想绕过限制强制解锁,基本上只有非常规手段。如果非要搞机,还是去选择一个官方支持解锁的厂商比较靠谱。不过,对于个人使用的主力机,我是不建议解锁的。上面提到过,解锁实际上是让设备启动过程中的某些安全机制失效;如果你解锁了 BL 的手机丢了或者由于某些原因被别人拿到,别人如果想要拿到你设备里面的数据,相比没有解锁的手机,要容易不止一个数量级。但愿这篇文章能有所启发,大家周末愉快!References lk(Little Kernel): https://github.com/littlekernel/lkZircon: https://fuchsia.googlesource.com/fuchsia/+/master/zircon/README.mdamonet: https://github.com/xyzz/amonetkamakiri: https://github.com/amonet-kamakiri/kamakiriCVE-2021-0467: https://source.android.com/security/bulletin/2021-05-01
关于 BootLoader 有过刷机经验或者曾经尝试过刷机的童鞋,一定听说过「解锁」这个词。这里的「解锁」全称应该是「解锁 BootLoader」或者简称为「解 BL 锁」。与通过人脸识别或者指纹、数字图案解锁手机屏幕的那种「屏幕解锁」不同,这里的「解锁」完全是另外一个概念。直观来说,解 BL 锁是刷机的前提条件。通常情况下,一旦某个设备无法解锁 BL,基本上就无法在这个设备进行刷机了。那么,一定会有童鞋关心,解锁 BootLoader 到底意味着什么?为什么它会有限制?我们能绕过限制强制解锁吗?今天,我就尝试来回答一下这几个问题。在搞清楚解锁 BootLoader 之前,我们必须先搞清楚什么是 BootLoader:{callout color="#00ffff"}A bootloader is software that is responsible for booting a computer.{/callout}维基百科上的介绍言简意赅:Bootloader 是负责启动计算机的软件。计算机开机的时候,会执行一个相对较小的程序来初始化内存、外设等启动后续操作系统必备的资源,并最终启动用户所使用的操作系统(如 Windows, Android 等);这个程序就是 BootLoader。我们知道,操作系统负责管理设备的硬件资源;而 BootLoader 是用来启动操作系统的,如果有人通过 BootLoader 来启动一个恶意的操作系统,那我们设备的安全性就无法得到保障了。因此,BootLoader 一个核心的功能就是,确保启动一个可信的操作系统。另外,当设备的操作系统出现问题时,BootLoader 还可以引导启动另外一个正常的可信系统来执行恢复;所以,BootLoader 另外一个功能重要功能就是恢复系统。具体来说,BootLoader 是如何实现这两大功能的呢?以高通设备为例,我们看一下 BootLoader 的启动流程: 当我们按下电源键启动手机的时候,CPU 上电之后开始运行;它最开始运行的代码是 CPU 芯片厂商提供的,写死在某个只读存储上,这段代码一旦出厂便不可更改,我们通常称之为 BootROM 或者 PBL (Primary Boot Loader);PBL 的主要功能是上电自检并启动下一个组件 SBL(Secondary Boot Loader),现在被叫做 XBL (eXtended Boot Loader)。这个 SBL 主要是初始化一些硬件环境(如DDR, clocks 和 USB 等)和代码安全环境 (TrustZone),当然,最重要的还是验证并加载下一个组件——ABL(Android Boot Loader,也叫 aboot)。与 PBL 不同,SBL 程序一般存放在 eMMC 上,这个地方是可以被修改的,因此它可以被刷写和升级。正因如此,SBL 还承载着最底层的恢复设备的重任;我们常说的高通 9008 模式(全称 Emergency Download Mode)就运行在这里。9008 模式,本质上就是强制刷写设备的 eMMC 存储,因此不论你上层操作系统或者应用软件被破坏成什么样,除非硬件损坏,基本上都可以救回来。有童鞋会问,为啥要整个 SBL,直接 PBL 一把干完不行吗?实际上,PBL 是芯片相关的,芯片无法预知到它用什么外设,因此这两个阶段被解耦了。话说回来,SBL 执行完之后会验证并加载 ABL,ABL 的主要功能是从设备验证并加载 bootimg 然后启动 Linux Kernel 进而启动用户操作系统,根据选择的不同,可能会进入到 Android 系统或者 Recovery 模式。ABL 还有一个很重要的功能,它提供了一个 fastboot 协议,用户可以用 PC 通过 USB 连接设备,通过这个 fastboot 协议控制设备;我们通常所说的「线刷」,小米的兔子界面以及我们通过命令行工具 fastboot 刷机实际上就是运行在 ABL 下。正因 ABL 功能比较复杂,它内部其实运行着一个 mini 的操作系统,这个操作系统就是 lk(Little Kernel),顺带一提,Trusty TEE 可信执行环境下的操作系统以及 Google 新的 Fuchsia 的微内核 Zircon 也是基于 lk 的。ABL 启动 Linux Kernel 之后,内核最终会进入用户态执行 init,init 进而启动 ueventd, watchdogd, surfaceflinger 以及 zygote 等;zygote 启动之后 fork system_server 并启动各种 binder 服务,系统核心 binder 服务启动之后会启动 Launcher 桌面,这样整个系统就启动完毕了。联发科的设备 BootLoader 启动过程类似: 从上述 BootLoader 启动过程,我们可以很清楚地知道,BootLoader 的恢复功能体现在 SBL 阶段的恢复模式以及 ABL 阶段的 fastboot 线刷模式。实际上,在我们手机底层软件出现问题之后,不论是自己救砖还是去售后,基本都是用的这两种模式。在搞清楚了 BootLoader 的恢复功能之后,那在安全性方面,它又是如何保障的呢?细心的童鞋可能会注意到,上面我们多次提到了验证并加载。BootLoader 的各个启动过程串起来就是一个启动链,这个启动链的各个阶段在进行过渡和跳转的时候是需要进行验证的。也就是说,上一阶段在启动下一阶段的时候,会验证下一阶段的代码是否可信;只有在验证通过的情况下,整个启动过程才会继续进行。这就好比接力赛跑,在上一个选手把接力棒传递到下一个选手之前,他得先搞清楚是不是把接力棒交到了正确的伙伴手里;在现实世界中,这是通过五官和记忆来判断的;在计算里面,这个验证的过程实际上就是比对数字签名。如果 BootLoader 的每一个阶段都严格验证数字签名,在代码逻辑都正确的情况下,用户是无法通过 BootLoader 去加载一个修改过的第三方系统的(也就是无法刷机)。那么什么是解锁 BootLoader?解锁 BootLoader 实际上就是让 BootLoader 启动链上某些阶段的签名验证不生效。如果让 BootROM 不验证 SBL,那我们就可以任意加载 XBL 从而接管接下来的操作流程如 TEE,lk, Linux Kernel;如果让 SBL 不验证 ABL,那我们就可以任意加载 ABL 从而接管 lk 和 Linux Kernel;如果让 ABL 不验证 boot.img,我们就可以控制 Linux Kernel。在现实场景中,人们最需要的就是刷入自定义 boot.img,毕竟这是用户能接触到的最上层系统 Android 的一部分。修改 TEE 和 LK 理论上不是不可以,但是修改这部分人们感知不强,并且通常这部分组件并不开源,也让很多人无从下手。因此实际上,我们通常所说的解锁 BootLoader 特指让 ABL(aboot) 在加载 bootimage 时不进行验证。某些设备厂商提供了解锁功能,实际上就是通过某种方式关闭了 ABL 中对 bootimage 的加载验证。也许有童鞋会想,我们想办法篡改这个签名,那不是就可以解锁了?比如我们可以这样操作:把 bootimage 修改并用自己的签名,然后把 ABL 中存放签名的地方暴力改成我们的签名;这样 ABL 在校验签名的时候就会通过。但问题是,如果我们要修改 ABL 中存放签名的地方,势必要修改 ABL,那么 SBL 在加载 ABL 的时候就会验证签名不通过;这样的话,我们继续修改 SBL,然后把 PBL 中存签名的地方改掉?看起来或许可以。实际上,整个启动链之所以能保障安全,是因为它的信任传递机制——正因为第一个角色可信,第二个角色才可信,并一步步向下传递。如果有办法破坏掉启动链的第一个角色,那就破坏了整个信任链。所以,在 BootLoader 启动过程中,PBL(BootROM) 所持有的签名是所有安全的基石,也即信任根(Root of Trust)。在 BootLoader 中,有两个机制确保信任根受信:1.BootROM 的代码存放在只读存储器中,一旦出厂不可更改。2.下一阶段的可信数字签名存放在独有的硬件设备之中(eFuse,一次性可编程存储器),一旦写入就会被破坏(三星设备解锁之后会「熔断」指的就是类似特性)。因此,如果所有的组件都按照理想情况下工作,我们就无法更改 BootROM 所持有的信任根,进而无法破坏启动过程中的信任链,也就无法解锁设备。当然,一切建立在所有的代码都正常工作的条件下。一旦某个阶段的代码有漏洞,那我们就有希望突破信任链,进而强制解锁设备。事实上,这种漏洞并非天方夜谭。iOS 上著名的 checkmate 漏洞就是 BootROM 中的代码存在问题,通过这个漏洞人们可以越狱设备,甚至引导另外一个操作系统(比如在 iOS 上运行 Android)。联发科的芯片,也曾经出现过不少 BootROM 漏洞,比如 amonet 和 最近的 kamakiri。今年五月份的安全更新中,CVE-2021-0467 也是一个 BootROM 漏洞。如果设备提供商偷懒,并没有完整地实现整个安全启动链,那也是可能强制解锁的。比如老的华为设备,其解锁码存放在 proinfo 分区下,这个分区是可以被刷写的;因此你可以拿别的设备的解锁码和 proinfo 分区刷入直接通过验证。还有,曾经的 vivo 对 bootimage 的验证并不严格,用户自定义一个 fastboot 就可以直接解锁。总体来说,如果想绕过限制强制解锁,基本上只有非常规手段。如果非要搞机,还是去选择一个官方支持解锁的厂商比较靠谱。不过,对于个人使用的主力机,我是不建议解锁的。上面提到过,解锁实际上是让设备启动过程中的某些安全机制失效;如果你解锁了 BL 的手机丢了或者由于某些原因被别人拿到,别人如果想要拿到你设备里面的数据,相比没有解锁的手机,要容易不止一个数量级。但愿这篇文章能有所启发,大家周末愉快!References lk(Little Kernel): https://github.com/littlekernel/lkZircon: https://fuchsia.googlesource.com/fuchsia/+/master/zircon/README.mdamonet: https://github.com/xyzz/amonetkamakiri: https://github.com/amonet-kamakiri/kamakiriCVE-2021-0467: https://source.android.com/security/bulletin/2021-05-01 -
何为root? 对于搞机党或者开发人员来说,root 一定是一个不陌生的名词。在 当我们谈论解锁 BootLoader 时,我们在谈论什么?一文中我们了解到,解锁 Bootloader 实际上能做到的是让手机可以运行第三方的操作系统,而通常来说,我们给手机解锁 Bootloader 就是为了获取 Root 权限。那么,何为root?,解锁 Bootloader 和 root 到底有什么联系和区别?{callout color="#f0ad4e"}In Unix-like computer OSes (such as Linux), root is the conventional name of the user who has all rights or permissions (to all files and programs) in all modes (single- or multi-user).{/callout}维基百科说,在类 Unix 系统中,root 是在所有模式(单用户或多用户)下对所有文件和程序拥有所有权利或许可的用户的名称。现代操作系统(本文主要讨论 Android 系统,下同)一般都是多用户的,那个名为 root 的用户所拥有的权限就是 root 权限;而 root 权限中有三个「所有」,可以简单这么理解:root意味着最高权限;不过,这么描述不够具象,接下来就带大家了解一下 root 的方方面面。{mtitle title="root的来源"/}在类 Unix 系统中, 一切皆文件。而这些文件通常以一个分层的树形结构在文件系统中呈现,每一个文件都有一个父目录,而那个最顶层的父目录被称之为根目录(root directory);root 用户之所以被称之为 root,大抵是因为它是唯一能修改 root directory 的用户。因为 root 用户拥有最高权限,因此它也通常被称之为超级用户(superuser);在类 Unix 系统中,每一个用户都有一个 ID,root 用户的 ID 是 0,从传统意义上讲,uid 为 0 就是 root 用户,也就拥有最高权限。{mtitle title="最高权限具体指的哪些"/}我们一直在说,「最高权限」,那么最高权限到底是哪些呢?直白点来说,手机是由多个零部件组成的,比如说,CPU、内存、闪存、各种硬件设备(如相机,屏幕、传感器等),所谓最高权限,就是对所有这些设备的控制权。对于 CPU 来说,现在的 CPU 芯片一般都有不同的特权等级,这些不同的等级可以执行不同的指令。就拿 AArch64 构架来说,CPU 有四个特权等级,EL0 ~ EL3: 在不考虑 Secure World 的情况下(感兴趣的可以 google TrustZone),EL0 就是通常所谓的用户空间,应用程序一般运行在 EL0 级别,操作系统(Linux 内核及驱动)运行在 EL1,EL2 上运行的则是虚拟化相关程序,EL3 则运行管理 Secure World 和 Normal Wrold 的 Secure Monitor。从严格意义上来说,既然 root 权限意味着最高权限,这应该代表着它可以在 EL0 ~ EL3 中的任意 level 上执行任意的 CPU 指令。然而,当前的各种 root 实现并非如此,它们一般能在 EL0 上执行任意指令,在某些情况下可以在 EL1 上执行任意指令;更高的特权等级就不行了。因为 root 用户是操作系统的概念,因此 root 权限顶多是操作系统中的最高权限;在我们的类 Unix 系统中,它仅能触及 EL1 也就不算奇怪了。对于内存、闪存以及各种外设来说,它们一般由操作系统内核和驱动来管理,而内核和驱动运行的指令通常位于 EL1,因此,root 权限意味着对所有的硬件(不包括 TEE 相关硬件)和外设拥有完全的控制权。总结一下就是,root 权限所拥有的最高权限,是我们的用户操作系统能管理的所有权限,包括各种硬件和外设以及一部分 CPU 指令的执行权限。{mtitle title="把权力关进笼子里"/}在过去的很长一段时间里,root 用户拥有的 root 权限代表着最高权限,它能实施一切特权行为;然而,这种模式有着相当大的安全风险。比如说,如果一个 root 用户执行了 rm -rf /命令(这种情况时有发生),那么整个系统就会瘫痪。可以看出,直接把最高权限暴露给用户并不明智;本着把权力关进笼子里的原则,root 用户所拥有的 root 权限逐渐被加上了各种限制;从此以后,root 权限并不能为所欲为了。SELinux SELinux 可能是最常见的一种权限控制手段。很多童鞋在刷机或者用框架的时候,会听到诸如「关闭 SELinux」,「开启宽容模式」,实际上就是对 SELinux 的控制。传统的权限控制是通过自主访问控制实现的,所谓「自主」指的是,这个文件的所有者主动决定哪些其他的用户可以访问它所拥有的文件。一般通过文件权限码和访问控制表来实现。我们通常所说的,文件可读可写可执行,就是文件权限码,除了 rwx 以外,SUID/SGID 也是常见的权限码,它代表某个程序在被 execve 之后会自动切换其 EUID。而访问控制表(ACL)是一种补充手段,它可以实施更加精细的自主访问控制,感兴趣的可以参考Linux 中的访问控制列表。由于自主访问控制是「自主的」,如果某个用户无意中实施了错误操作(如rm -rf /),那么整个系统就不受控了,因此强制访问控制(MAC)应运而生,而 SELinux 则是 MAC 的一种具体实现。 所谓强制访问控制,就是每当主体(通常是进程)尝试访问对象(文件)时,都会由操作系统内核强制施行授权规则,由这些特殊的规则来决定是否授予权限;这些规则是独立于文件权限码之外的,因此,即使某个用户(如 root)是某个文件的所有者,通过这些额外的规则,可以让这个用户无法对这个文件执行某些操作。通常情况下,root 用户也有权限关闭 SELinux 的部分功能(如开启宽容模式),这种情况下 SELinux 的大部分机制会失效,使得 root 用户可以避开 SELinux 的限制。而我们所使用的一些 root 技术实现(如 Supersu, Magisk 等),会给 SELinux 系统添加一些特殊的规则,可以在不关闭 SELinux 的条件下,让我们的 root 用户绕过 SELinux 的限制,进而拥有传统意义上的超级权限。在现代的 Android 系统中,如果 root 用户不幸运行在 SELinux Enforcing 状态下,而系统又没有为其开绿灯(定义特殊规则),那么它所能做的操作相当有限,某种程度上甚至连普通用户都不如,表现起来就像是个「残废」。capabilities 除了强制访问控制以外,实际上 Linux 系统中还有一些其他的机制来限制超级权限。在传统的权限控制中,系统一刀切地把权限分为超级权限(privileged)和普通权限(unprivileged),特权用户可以绕过所有的系统限制,而普通用户则受限于其权限位;这种方式有着明显的缺陷:如果普通用户想要执行某一个特殊操作,那它只能切换到特权用户,然而一旦切换到特权用户,它就拥有了所有的特殊权限;那么恶意用户就可以挂羊头卖狗肉,表面上说我只是想读个文件,结果切换到特权用户之后直接把你其他重要东西删了。因此,Linux 系统引入了 capabilities 机制,这种机制把超级权限划分为若干种权限,按照需要给普通用户分配,很好地解决了一刀切的问题。比如说CAP_NET_ADMIN定义了与各种网络操作相关的权限CAP_SETUID定义了用户是否可以任意改变自己的 uid;这些不同的 capabilities 可以组合起来形成某个权限范围,从而实现权限的细分。更多的 capabilities 可以参考Linux man page和linux-capabilities-in-a-nutshell。 我们在实现某些 root 机制的时候,如果没有处理好 capabilities 的问题,就会出现各种类似残废 root 的情况,比如 root 用户无法访问网络等。seccomp 严格来讲,seccomp 并不算是一种安全策略,不过这种机制也能对我们的 root 用户实施某些限制;这里也简单滴介绍一下。seccomp 是secure computing mode的缩写,它是内核的一种安全计算机制,这种机制可以对进程能执行的系统调用(与内核打交道的机制)做出一些限制。 在传统的 seccomp 中,某个进程可以通过这种机制进入一种不可逆转的状态,在这种状态下,它只能执行exit,sigreturn,read,write这几个系统调用;后来人们发现对进程的系统调用添加限制还挺有用,于是拓展了 seccomp,让它可以通过某种自定义的策略来限制特定的系统调用(而不是写死的 exit,read 那几个),也就是 seccomp-bpf。与 capabilities 类似,如果某种 root 机制没有处理好 seccomp 的问题,同样会出现「残废 root 的情况。内核模块加载验证 我们前面提到,在 AArch64 中,操作系统内核运行在 CPU 的 EL1 特权模式中;然而,我们通常所使用的 root 机制并不能让我们任意地在 EL1 中执行指令,也就是说,我们现在用到的 root 机制,实际上是 EL0 root。在 Linux 内核中,root 用户可以通过一种被称之为可加载内核模块(LMK)的机制来在内核空间(EL1 级别)执行代码。简单来说,就是写一个内核模块,然后通过insmod或者modprob将此模块动态注册到内核之中执行;这样我们的 root 用户实际上就拥有了 CPU 的 EL1 执行权限。然而不幸的是,现代 Android 系统对内核模块加载通常有验证机制,它不允许任意加载模块。通常的验证方式有两种:vermagic 验证签名验证vermagic 验证是因为 Linux 不保证内核模块的跨版本兼容性,因此在某个内核版本编译出来的模块被禁止在另外一个版本上运行;它通过内核版本号和导出符号的布局来限制模块的加载,避免出现模块和内核间不同版本的兼容性问题。签名验证就是一种纯粹的安全机制,在开启这个机制之后,内核拒绝加载未经验证过的签名的模块;与解锁 Bootloader 一样,这个签名通常在设备制造商手里,第三方签名的模块无法被加载。简单来说,内核模块加载验证机制在某种程度上阻止了我们对 EL1 级别权限的获取,目前我们所使用的 root 实现被限制在 EL0,无法实现更高级别的特权操作。{mtitle title="实现 root 访问"/}前面我们描述了 root 权限所能执行的操作和为了限制超级权限做出的一些特殊机制,那么,在 Android 系统中,我们如何获取 root 权限呢?实现 root 的方式整体上可以分为两种:1.解锁 Bootloader,通过修改 Android 系统的某一部分实现 root。2.通过某些系统漏洞提取,进而获取 root 权限。我们在前文可以知道,解锁 Bootloader 实际上就允许我们刷入第三方或者被修改过的操作系统;如果我们可以解锁 Bootloader,那么理论上讲我们就可以任意修改其操作系统,而 root 权限只不过是操作系统的某种机制,因此获取 root 权限自然不在话下。而这种修改方式常见的如下:1.通过直接刷入第三方系统实现;在这个第三方系统中,系统自带 root 权限。2.通过修改原系统的init实现;因为 init 进程是 Linux 系统的第一个进程,因此它实际上就以 root 身份执行的;通过修改 init 也可以实现 root 访问;Magisk 就是通过代理 init 实现的 root 权限。3.通过自定义内核实现;因为 root 权限实际上是内核操控的,因此自定义内核然后刷入自然可以获取 root 权限。如果我们不能解锁 Bootloader,那么可以通过系统漏洞来提权,进而拥有 root 权限。在远古时代(特别是 Android 6.0 以前),各种一键 root 满天飞,比如 kingroot,360 一键 root,他们本质上都是通过系统漏洞来获取特殊权限;然而,随着 Android 系统的演进,这种通过漏洞提权获取 root 的方式已经很难出现在普通的大众视野里面了。我曾经提到太极有一种「少阳」模式,它就是通过这种方式来提权,进而实现不解锁就能对系统进程加载模块的;然而由于这种方式实际上就是利用漏洞,从机制上讲并不长久,因此被永久雪藏。如果我们通过系统漏洞提权,那么必须妥善处理好我上面所介绍的各种限制,如绕过 SELinux,关闭 seccomp,获取所有 capabilities,否则提权之后的 root 基本就是个残废;然而,绕过这所有的机制并无一个稳定可用的方法,再加上 Android 系统的碎片化,导致通过漏洞获取通杀 root 权限的实现成本变得非常之高。{mtitle title="root的过去和现在"/}上面我们介绍了一些 root 权限的获取方式,那么具体来说,从 Android 诞生到现在,我们实际上所使用的 root 方案,具体是哪种机制呢?在 Android 系统的远古时代,root 方案基本上是通过 SUID 实现的。在上文描述 capabilities 和自主访问控制的时候我们提到过这种机制。SUID是一个特殊的权限位,它的特殊之处在于,如果某个可执行文件设置了这个权限位,某个用户在执行这个文件的之后,启动进程的 uid 会被自动切换为文件所有者的 uid。打个比方,假设我有个文件名叫su,它的所有者是 root,其他进程有其可执行权限;如果没有设置 SUID,那么某个进程比如 uid 为 10000,在执行这文件之后,它启动的进程实际 uid 也是 10000,也就是一个普通进程;而如果这个文件有被设置 SUID 位,那么 uid 为 10000 的用户在执行这个文件之后,所启动的进程 uid 会被自动切换为文件所有者,也就是 root 用户,这个进程就是一个特权进程。用这种方式实现 root 可谓是非常简单,只需要丢一个 SUID 的文件到系统里面就结束了。然而,Android 4.3 系统的安全性改进让这种机制退出了历史舞台。这种机制其实非常简单,就是通过我们上文提到的 capabilities 机制,给 zygote 的子进程限制了 CAP_SETUID;而我们的 Android App 都是 zygote 子进程,因此 App 从此与 SUID root 告别了。然而,我们的 shell 用户还是可以 SUID 的;某些系统中自带的su还是这种 SUID 的 root,在这种系统中我们会发现,adb shell 可以获取 root 权限,但是 App 进程死活无法获取 root,这时候可以看一下su文件是否有 SUID 位,如果有的话就是这个原因。在没有 SUID 之后,App 进程是无法 fork 一个 uid 为 0 的子进程的;从此以后,我们常见的 root 实际上是一种「远程 root 进程」。因为我们的 App fork 出来的进程 uid 不能被改为 0,因此这个进程肯定无法变成 root 进程,怎么办呢?我们可以启动一个远程的特权进程,这个进程的 uid 是 0(比如从 init fork 出来),一旦我们的 App 需要使用 root,那就从 App fork 出一个子进程,让这个子进程与那个远程的特权进程关联起来,我们想要执行 root 命令的时候,还是与以前一样让这个子进程去做,不同的是,这个子进程实际上并不会执行这些命令,而是把命令发给那个远程的特权进程让它去执行,特权进程执行完毕之后把结果再返回给子进程,这样也实现了我们所需要的 root 访问。你可以简单地把我们 fork 出来的子进程当作那个远程特权进程的代理,所以我把这种方式称之为「远程 root 进程」。现在的Supersu 和 MagiskSU 都是通过这种方式实现的,如果你在 Magisk 下执行一个 root 命令,你会发现除了你自已的su进程之外,还会有一个 magiskd 的进程,这两个进程会通过 UDS(Unix Domain Socket) 通信,有很多 Magisk 检测手段就是通过检测 UDS 实现的。{mtitle title="root的未来"/}从上文我们可以了解到,当前的各种 root 实现本质上都是 EL0 root。由于这种 root 的实现机制本质上运行在用户空间,它始终有其局限性;我们需要一个 EL1 root!我认为,随着 GKI 的出现,内核的碎片化会逐渐消失,我们完全可以通过修改内核的方式去获取 EL1 root。无比期待这种新的 root 方式的到来。{mtitle title="后记"/}本文酝酿了很久,现在终于写完了,如释重负!如果不当之处或者技术性错误,还请海涵!但愿能帮到大家,晚安!References Linux 中的访问控制列表: https://documentation.suse.com/zh-cn/sled/15-SP2/html/SLED-all/cha-security-acls.htmlLinux man page: https://man7.org/linux/man-pages/man7/capabilities.7.htmllinux-capabilities-in-a-nutshell: https://k3a.me/linux-capabilities-in-a-nutshell/secure computing mode: https://en.wikipedia.org/wiki/SeccompSUID: https://en.wikipedia.org/wiki/SetuidAndroid 4.3 系统的安全性改进: https://source.android.com/security/enhancements/enhancements43GKI 的到来: https://source.android.com/devices/architecture/kernel/generic-kernel-image
-
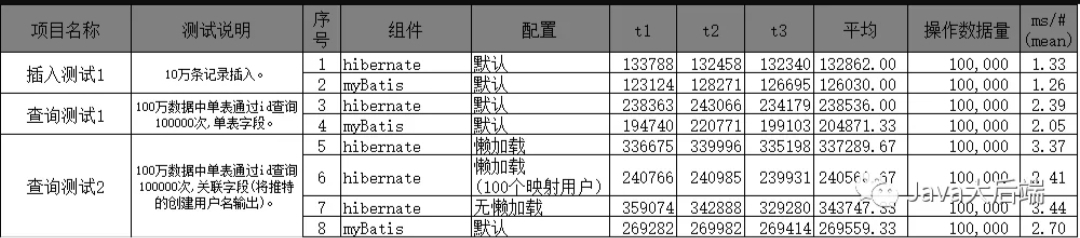
MyBatis vs Hibernate,到底哪个性能更好? 前言由于编程思想与数据库的设计模式不同,生出了一些ORM框架。核心都是将关系型数据库和数据转成对象型。当前流行的方案有Hibernate与myBatis。两者各有优劣。竞争激烈,其中一个比较重要的考虑的地方就是性能。因此笔者通过各种实验,测出两个在相同情景下的性能相关的指数,供大家参考。测试目标以下测试需要确定几点内容:性能差异的场景;性能不在同场景下差异比;找出各架框优劣,各种情况下的表现,适用场景。测试思路测试总体分成:单表插入,关联插入,单表查询,多表查询。测试分两轮,同场景下默认参数做一轮,调优做强一轮,横纵对比分析了。测试中尽保证输入输出的一致性。样本量尽可能大,达到10万级别以上,减少统计误差。测试提纲具体的场景情况下:插入测试1:10万条记录插入。查询测试1:100万数据中单表通过id查询100000次,无关联字段。查询测试2:100万数据中单表通过id查询100000次,输出关联对象字段。查询测试3:100万*50万关联数据中查询100000次,两者输出相同字段。准备数据库:mysql 5.6表格设计:twitter:推特CREATE TABLE `twitter` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `add_date` datetime DEFAULT NULL, `modify_date` datetime DEFAULT NULL, `ctx` varchar(255) NOT NULL, `add_user_id` bigint(20) DEFAULT NULL, `modify_user_id` bigint(20) DEFAULT NULL, PRIMARY KEY (`id`), KEY `UPDATE_USER_FORI` (`modify_user_id`), KEY `ADD_USER_FORI` (`add_user_id`), CONSTRAINT `ADD_USER_FORI` FOREIGN KEY (`add_user_id`) REFERENCES `user` (`id`) ON DELETE SET NULL, CONSTRAINT `UPDATE_USER_FORI` FOREIGN KEY (`modify_user_id`) REFERENCES `user` (`id`) ON DELETE SET NULL) ENGINE=InnoDB AUTO_INCREMENT=1048561 DEFAULT CHARSET=utf8user: 用户CREATE TABLE `user` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=524281 DEFAULT CHARSET=utf8数据准备:表一:twitter无数据。表二:user50万个随机的用户名。随机内容推特表(material_twitter)无id,仅有随机字符串内容,共10万条。用于插入控推特表。生成数据代码,关联100个用户:insert into twitter(ctx,add_user_id,modify_user_id,add_date,modify_date)SELECT name,ROUND(RAND()*100)+1,ROUND(RAND()*100)+1,'2016-12-31','2016-12-31'from MATERIAL生成数据代码,关联500000个用户:insert into twitter(ctx,add_user_id,modify_user_id,add_date,modify_date)SELECT name,ROUND(RAND()*500000)+1,ROUND(RAND()*500000)+1,'2016-12-31','2016-12-31'from MATERIAL实体代码:@Entity@Table(name = "twitter")public class Twitter implements java.io.Serializable{ private Long id; private Date add_date; private Date modify_date; private String ctx; private User add_user; private User modify_user; private String createUserName; @Id @GeneratedValue(strategy = IDENTITY) @Column(name = "id", unique = true, nullable = false) public Long getId() { return id; } public void setId(Long id) { this.id = id; } @Temporal(TemporalType.DATE) @Column(name = "add_date") public Date getAddDate() { return add_date; } public void setAddDate(Date add_date) { this.add_date = add_date; } @Temporal(TemporalType.DATE) @Column(name = "modify_date") public Date getModifyDate() { return modify_date; } public void setModifyDate(Date modify_date) { this.modify_date = modify_date; } @Column(name = "ctx") public String getCtx() { return ctx; } public void setCtx(String ctx) { this.ctx = ctx; } @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "add_user_id") public User getAddUser() { return add_user; } public void setAddUser(User add_user) { this.add_user = add_user; } @ManyToOne(fetch = FetchType.LAZY) @JoinColumn(name = "modify_user_id") public User getModifyUser() { return modify_user; } public void setModifyUser(User modify_user) { this.modify_user = modify_user; } @Transient public String getCreateUserName() { return createUserName; } public void setCreateUserName(String createUserName) { this.createUserName = createUserName; }}开始插入测试1代码操作:将随机内容推特表的数据加载到内存中,然后一条条加入到推特表中,共10万条。关键代码:hibernate:Session session = factory.openSession();session.beginTransaction();Twitter t = null;Date now = new Date();for(String materialTwitter : materialTwitters){// System.out.println("materialTwitter="+materialTwitter); t = new Twitter(); t.setCtx(materialTwitter); t.setAddDate(now); t.setModifyDate(now); t.setAddUser(null); t.setModifyUser(null); session.save(t);}session.getTransaction().commit();mybatis:Twitter t = null;Date now = new Date();for(String materialTwitter : materialTwitters){// System.out.println("materialTwitter="+materialTwitter); t = new Twitter(); t.setCtx(materialTwitter); t.setAddDate(now); t.setModifyDate(now); t.setAddUser(null); t.setModifyUser(null); msession.insert("insertTwitter", t);}msession.commit();TwitterMapper.xml,插入代码片段:<insert id="insertTwitter" keyProperty="id" parameterType="org.pushio.test.show1.entity.Twitter" useGeneratedKeys="true"> insert into twitter(ctx, add_date,modify_date) values (#{ctx},#{add_date},#{modify_date})</insert>查询测试1通过id从1递增到10万依次进行查询推特内容,仅输出微博内容。关键代码:hibernate:long cnt = 100000; for(long i = 1; i <= cnt; ++i){ Twitter t = (Twitter)session.get(Twitter.class, i); //System.out.println("t.getCtx="+ t.getCtx() + " t.getUser.getName=" + t.getAddUser().getName()); }mybatis:long cnt = 100000; for(long i = 1; i <= cnt; ++i){ Twitter t = (Twitter)msession.selectOne("getTwitter", i); //System.out.println("t.getCtx="+ t.getCtx() + " t.getUser.getName=" + t.getAddUser().getName()); }查询测试2与查询测试1总体一样,增加微博的创建人名称字段,此处需要关联。其中微博对应有10万个用户。可能一部份用户重复。这里对应的用户数可能与hibernate配懒加载的情况有影响。此处体现了hibernate的一个方便处,可以直接通过getAddUser()可以取得user相关的字段。然而myBatis则需要编写新的vo,因此在测试batis时则直接在Twitter实体中增加创建人员名字成员(createUserName)。此处hibernate则会分别测试有懒加载,无懒加载。mybatis会测有默认与有缓存两者情况。其中mybatis的缓存机制比较难有效配置,不适用于真实业务(可能会有脏数据),在此仅供参考。测试时,对推特关联的用户数做了两种情况,一种是推特共关联了100个用户,也就是不同的推特也就是在100个用户内,这里的关联关系随机生成。另外一种是推特共关联了50万个用户,基本上50个用户的信息都会被查询出来。在上文“准备”中可以看到关联数据生成方式。关键代码:hibernate:long cnt = 100000; for(long i = 1; i <= cnt; ++i){ Twitter t = (Twitter)session.get(Twitter.class, i); t.getAddUser().getName();//加载相应字段 //System.out.println("t.getCtx="+ t.getCtx() + " t.getUser.getName=" + t.getAddUser().getName()); }急懒加载配置更改处,Twitter.java:@ManyToOne(fetch = FetchType.EAGER)//急加载 //@ManyToOne(fetch = FetchType.LAZY)//懒加载 @JoinColumn(name = "add_user_id") public User getAddUser() { return add_user; }mybatis:for(long i = 1; i <= cnt; ++i){ Twitter t = (Twitter)msession.selectOne("getTwitterHasUser", i); // System.out.println("t.getCtx="+ t.getCtx() + " t.getUser.getName=" + t.getCreateUserName()); }TwitterMapper.xml配置:<select id="getTwitterHasUser" parameterType="long" resultType="org.pushio.test.show1.entity.Twitter"> select twitter.*,user.name as creteUserName from twitter,user where twitter.id=#{id} AND twitter.add_user_id=user.id </select>测试结果测试分析测试分成了插入,单表查询,关联查询。关联查询中hibernate分成三种情况进行配置。其中在关联字段查询中,hibernate在两种情况下,性能差异比较大。都是在懒加载的情况下,如果推特对应的用户比较多时,则性能会比仅映射100个用户的情况要差很多。换而言之,如果用户数量少(关联的总用户数)时,也就是会重复查询同一个用户的情况下,则不需要对用户表做太多的查询。其中通过查询文档后,证明使用懒加载时,对象会以id为key做缓存,也就是查询了100个用户后,后续的用户信息使用了缓存,使性能有根本性的提高。甚至要比myBatis更高。如果是关联50万用户的情况下,则hibernate需要去查询50万次用户信息,并组装这50万个用户,此时性能要比myBatis性能要差,不过差异不算大,小于1ms,表示可以接受。其中hibernate非懒加载情况下与myBatis性能差异也是相对其他测试较大,平均值小于1ms。这个差异的原因主要在于,myBatis加载的字段很干净,没有太多多余的字段,直接映身入关联中。反观hibernate则将整个表的字都会加载到对象中,其中还包括关联的user字段。hibernate这种情况下有好有坏,要看具体的场景,对于管理平台,需要展现的信息较多,并发要求不高时,hibernate比较有优势。然而在一些小活动,互联网网站,高并发情况下,hibernate的方案太不太适合,myBatis+VO则是首选。测试总结总体初观,myBatis在所有情况下,特别是插入与单表查询,都会微微优于hibernate。不过差异情况并不明显,可以基本忽略差异。差异比较大的是关联查询时,hibernate为了保证POJO的数据完整性,需要将关联的数据加载,需要额外地查询更多的数据。这里hibernate并没有提供相应的灵活性。关联时一个差异比较大的地方则是懒加载特性。其中hibernate可以特别地利用POJO完整性来进行缓存,可以在一级与二级缓存上保存对象,如果对单一个对象查询比较多的话,会有很明显的性能效益。以后关于单对象关联时,可以通过懒加载加二级缓存的方式来提升性能。最后,数据查询的性能与orm框架关无太大的关系,因为orm主要帮助开发人员将关系数据转化成对象型数据模型,对代码的深析上来看,hibernate设计得比较重量级,对开发来说可以算是重新开发了一个数据库,不让开发去过多关心数据库的特性,直接在hibernate基础上进行开发,执行上分为了sql生成,数据封装等过程,这里花了大量的时间。然而myBatis则比直接,主要是做关联与输出字段之间的一个映射。其中sql基本是已经写好,直接做替换则可,不需要像hibernate那样去动态生成整条sql语句。好在hibernate在这阶段已经优化得比较好,没有比myBatis在性能上差异太多,但是在开发效率上,可扩展性上相对myBatis来说好太多。最后的最后,关于myBatis缓存,hibernate查询缓等,后续会再专门做一篇测试。关于缓存配置myBatis相对Hibernate 等封装较为严密的ORM 实现而言,因为hibernate对数据对象的操作实现了较为严密的封装,可以保证其作用范围内的缓存同步,而ibatis 提供的是半封闭的封装实现,因此对缓存的操作难以做到完全的自动化同步。以上的缓存配置测试仅为性能上的分析,没有加入可用性上的情况,因为myBatis直接配置缓存的话,可能会出现脏数据,。在关联查询数据的情况下,hiberntae的懒加载配二级缓存是个比较好的方案(无脏数据),也是与myBatis相比有比较明显的优势。此情景下,性能与myBatis持平。在真实情况下,myBatis可能不会在这个地方上配置缓存,会出现脏数据的情况,因而很有可能在此hibernate性能会更好。
-
Linux环境下简单搭建Minecraft服务器(java版) 服务器可以使用国内的,保证延迟低,服务器配置一定要高一点,不然很容易Killed安装javadnf install java-openjdk检测java是否安装成功java -version新建一个目录mkdir hallomccd hallomc下载第三方mc服务器wget -c https://papermc.io/api/v2/projects/paper/versions/1.16.5/builds/553/downloads/paper-1.16.5-553.jar这是1.16.5的版本,服务器版本和客户端版本要一致历史版本https://papermc.io/legacy运行mc服务器java -Xmx1024M -Xms512M -jar paper-1.16.5-553.jarXmx 代表服务器启动所占的最大运行内存,Xms代表服务器正常运行的最大内存一般来说第一次运行都是运行不了,因为没有同意协议进入mc目录下,nano eula.txt,把eula=false改成eula=true,然后再运行mc服务器24小时运行mc服务端一般来说退出ssh登录,就会终止运行mc服务端,可以通过简单建立个“虚拟终端”,来24小时运行dnf install screen # 安装screenscreen -S mcserver # 创建一个新“终端”,名称自定义screen -R mcserver # 进入这个新“终端”如果想退出,可以使用ctrl+a+d可以使用screen -ls 命令来查看所有“终端”关闭正版验证在服务端目录,找到server.properties文件修改这个文件,把onlinemode 改为 false